

DeepSeek使用率暴跌至3%,生态豪赌堪忧

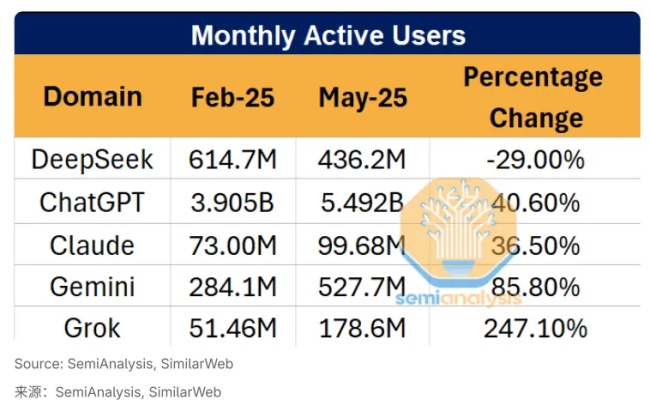
2025年Q2,DeepSeek官网流量下滑29%,而ChatGPT同期增长15%,Claude用户数更是翻倍。这不是一次偶然的震荡,而像一记闷棍,敲醒国产大模型的幻梦。
就在流量腰斩的同一周,DeepSeek宣布全面开源,CEO周林高调喊出“商业化不着急”。
一边是用户大撤退,一边是战略急刹车,这种“技术先行”的打法,究竟是远谋,还是误判?

生态渗透
官网流量下滑29%,一时间,“DeepSeek哑火”的声音此起彼伏。
Semianalysis的分析报告更像火上浇油,用一组C端数据下结论,直接判了死刑。
但真正懂行业的人知道,这不是“掉队”,而是“转向”。
腾讯元宝接入DeepSeek模型后,调用量一个月内暴涨40%,甚至在微信搜索场景中默认调用;百度文心一言在API调度上,也悄悄将DeepSeek设为优先备选。这场看不见的整合,比官网PV更能说明AI模型的真实渗透力。
这像极了2018年抖音初期靠微博外链、知乎视频“偷流量”的野路子——不是不增长,而是不在你以为的地方增长。
对比更直观:Anthropic的API月调用量波动高达20%,但C端访问量几乎不做披露;Mistral干脆把官网变成空壳,靠开源和社区走红,估值却依然飙到70亿美元。数据悖论越来越明显:当AI产品由ToC转ToB,C端流量已经不再是“胜负手”。
DeepSeek其实早就踩准了切换节点:开源MoE架构、B端低延时方案、与大厂联运……这一整套打法,更像是国产版的Anthropic。真正的竞争力,不在于有没有App图标,而在于谁能成为AI底座里的“隐身玩家”。
用官网流量唱衰一个AI公司,像用超市日客流评估亚马逊AWS。这不是结论的问题,是维度就错了。
更残酷的是:这种错维度的判断,正成为中国AI早期洗牌的“审判锤”。

生态豪赌
DeepSeek这波开源,不是“利他主义”,而是“卡位优先”。
它不靠ToC吸粉,也不走ToB签单,直接从底层模型开刀,用“免费”让云厂商站队、让开发者用脚投票,像极了当年共享单车抢占人行道的打法。
阿里云、华为云已适配DeepSeek模型。
360干脆用DeepSeek替代部分自研搜索模块。
它不求一锤子买卖,而是在打造一个“不可替代的模型默认选项”,比拼的不是营收,而是触点数量、调用频率和模型生态里的存在感。开源不是技术布施,是商业战略。
谁被更多平台集成,谁就拥有未来分发权。
但这种打法对现金流极不友好。DeepSeek没有广告主托底,没有大模型平台红利,选择把商业化收入让出去,只为换来一张“AI底座”的牌桌入场券。
2024年,其研发投入占比超35%。商业化收入占比约为12%。
看上去像是“烧钱自嗨”,实则是押注开发者生态的冷启动。Meta开源Llama3时背后有Facebook输血,DeepSeek只能靠“用爱发电”顶住财报压力。
问题在于,模型开源已成行业共识,但“免费”不等于“可持续”。
Mistral靠开源拿下政府大单,Cohere虽然没热度,但靠企业级稳稳变现,DeepSeek既没欧美政府订单,也缺强toB能力,全靠技术信仰维系生存。

它在赌一个时间差——赌资本还愿意相信未来、赌国内生态还没闭环、赌自己能在烧光预算前被“接盘”或跑出规模。
这种结构极像2000年代的互联网:先烧用户数、拼覆盖率,再谈变现逻辑,只不过把“流量池”换成了“调用量”。
问题是,这一轮AI热退潮太快,资本耐心正在消失。
如果接入平台迟迟不转化为营收,模型调用量成了无用KPI;如果开源模型无法沉淀差异化价值,调用越多反而暴露“边际成本高、护城河低”的痛点。
DeepSeek现在面临的局面,不是“卷不开源”,而是“开源变现两头空”。
它在用生态换时间、用调用换位置,但行业留给它的窗口,未必撑得到那一天。

硬伤与暗战
DeepSeek的模型,一度被吹成“国产最像GPT”的那一个。
可真用起来,用户集体抱怨它是“乖宝宝AI”——回答内容温吞克制、标准流程化,甚至连“番茄炒蛋”都得加一句“谨慎操作”。
技术指标也不乐观。
实测长文本理解错误率比GPT-4o高12%。多轮对话频现“记忆断裂”“上下文失联”。
它在安全性和能力边界之间,做了极度保守的权衡,换来的是泛用性模型的“及格表现”,却错失在单一场景内深扎能力的机会。
豆包已拿下50%的企业OA场景。阿里通义千问主攻医疗与客服问答。而DeepSeek仍在强调“通用AGI”,理想主义得像在搭建一个“人人可用”的科幻底座,却始终落不到具体场景的“刚需点”上。
这不是模型能力的问题,而是路线选择的问题。
在企业争相抢夺政企、教育、金融、客服等“高频刚需”领域时,DeepSeek还在用论文式训练目标、OpenAI式开放语料库、近乎宗教式的AGI设想与现实脱钩。

它赌的是长期爆发,但现实是短期绞杀。
云厂商拼SaaS交付效率、终端厂拼语音助手唤醒率、政府客户要可控、安全、本地化部署,没人再花时间“评测”你的哲学理想。
深度垂类落地这件事,已经在绕开它推进了。
开源成了一个好看的门面,企业客户用你的模型调研开发,用完就上自家平台部署;开发者在社区做点实验,一旦跑不动、精度差就换别家。
对DeepSeek来说,模型再强也只能是个“可替代工具”,不是“必选项”。
问题的核心不是没技术,而是没“被迫使用”的理由。
它像极了塞班时代的诺基亚,拥有强大内核,却错判了交互逻辑;也像特斯拉在FSD1.0时期,硬抗整个自动驾驶行业,只为抢先定义AGI语法。
但这次,它不再是唯一的特斯拉,也不是手机里的苹果。
行业已经有太多可用方案,尤其是国产大模型生态,在2025年之后,已从“百模大战”进入“场景围猎”,从“能力卷”走向“链路抢”。
DeepSeek押注的,是2025年前能实现多模态重大突破。
它的终极愿景,是像iPhone定义交互那样,用AGI直接跳过所有垂直应用,以“万金油”反包垂类冠军。
问题是,现在这副牌,逻辑没错,但牌面不够。
生态迟迟没有闭环,场景落地跟不上节奏,调用量再多也是空耗算力、无法变现;而技术短板暴露的越明显,被“边缘化”的速度也会越快。
这不是“模型不够强”,而是“模型没人用”。
·End·
*以上内容系网友风平浪静自行转载自爆财局,该文仅代表原作者观点和态度。本站系信息发布平台,仅提供信息存储空间服务,不代表赞同其观点和对其真实性负责。如果对文章或图片/视频版权有异议,请邮件至我们反馈,平台将会及时处理。