

DeepSeek使用率暴跌至3%,生態豪賭堪憂

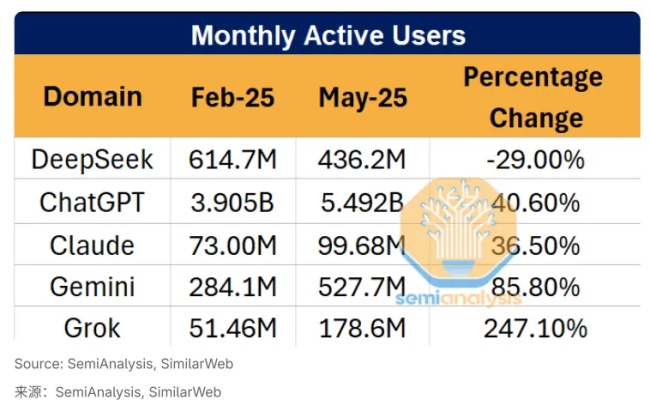
2025年Q2,DeepSeek官網流量下滑29%,而ChatGPT同期增長15%,Claude用戶數更是翻倍。這不是一次偶然的震蕩,而像一記悶棍,敲醒國產大模型的幻夢。
就在流量腰斬的同一周,DeepSeek宣布全面開源,CEO周林高調喊出「商業化不著急」。
一邊是用戶大撤退,一邊是戰略急剎車,這種「技術先行」的打法,究竟是遠謀,還是誤判?

生態滲透
官網流量下滑29%,一時間,「DeepSeek啞火」的聲音此起彼伏。
Semianalysis的分析報告更像火上澆油,用一組C端數據下結論,直接判了死刑。
但真正懂行業的人知道,這不是「掉隊」,而是「轉向」。
騰訊元寶接入DeepSeek模型后,調用量一個月內暴漲40%,甚至在微信搜索場景中默認調用;百度文心一言在API調度上,也悄悄將DeepSeek設為優先備選。這場看不見的整合,比官網PV更能說明AI模型的真實滲透力。
這像極了2018年抖音初期靠微博外鏈、知乎視頻「偷流量」的野路子——不是不增長,而是不在你以為的地方增長。
對比更直觀:Anthropic的API月調用量波動高達20%,但C端訪問量幾乎不做披露;Mistral乾脆把官網變成空殼,靠開源和社區走紅,估值卻依然飆到70億美元。數據悖論越來越明顯:當AI產品由ToC轉ToB,C端流量已經不再是「勝負手」。
DeepSeek其實早就踩准了切換節點:開源MoE架構、B端低延時方案、與大廠聯運……這一整套打法,更像是國產版的Anthropic。真正的競爭力,不在於有沒有App圖標,而在於誰能成為AI底座里的「隱身玩家」。
用官網流量唱衰一個AI公司,像用超市日客流評估亞馬遜AWS。這不是結論的問題,是維度就錯了。
更殘酷的是:這種錯維度的判斷,正成為中國AI早期洗牌的「審判錘」。

生態豪賭
DeepSeek這波開源,不是「利他主義」,而是「卡位優先」。
它不靠ToC吸粉,也不走ToB簽單,直接從底層模型開刀,用「免費」讓雲廠商站隊、讓開發者用腳投票,像極了當年共享單車搶佔人行道的打法。
阿里雲、華為雲已適配DeepSeek模型。
360乾脆用DeepSeek替代部分自研搜索模塊。
它不求一鎚子買賣,而是在打造一個「不可替代的模型默認選項」,比拼的不是營收,而是觸點數量、調用頻率和模型生態里的存在感。開源不是技術布施,是商業戰略。
誰被更多平台集成,誰就擁有未來分發權。
但這種打法對現金流極不友好。DeepSeek沒有廣告主托底,沒有大模型平台紅利,選擇把商業化收入讓出去,只為換來一張「AI底座」的牌桌入場券。
2024年,其研發投入佔比超35%。商業化收入佔比約為12%。
看上去像是「燒錢自嗨」,實則是押注開發者生態的冷啟動。Meta開源Llama3時背後有Facebook輸血,DeepSeek只能靠「用愛發電」頂住財報壓力。
問題在於,模型開源已成行業共識,但「免費」不等於「可持續」。
Mistral靠開源拿下政府大單,Cohere雖然沒熱度,但靠企業級穩穩變現,DeepSeek既沒歐美政府訂單,也缺強toB能力,全靠技術信仰維繫生存。

它在賭一個時間差——賭資本還願意相信未來、賭國內生態還沒閉環、賭自己能在燒光預算前被「接盤」或跑出規模。
這種結構極像2000年代的互聯網:先燒用戶數、拼覆蓋率,再談變現邏輯,只不過把「流量池」換成了「調用量」。
問題是,這一輪AI熱退潮太快,資本耐心正在消失。
如果接入平台遲遲不轉化為營收,模型調用量成了無用KPI;如果開源模型無法沉澱差異化價值,調用越多反而暴露「邊際成本高、護城河低」的痛點。
DeepSeek現在面臨的局面,不是「卷不開源」,而是「開源變現兩頭空」。
它在用生態換時間、用調用換位置,但行業留給它的窗口,未必撐得到那一天。

硬傷與暗戰
DeepSeek的模型,一度被吹成「國產最像GPT」的那一個。
可真用起來,用戶集體抱怨它是「乖寶寶AI」——回答內容溫吞克制、標準流程化,甚至連「番茄炒蛋」都得加一句「謹慎操作」。
技術指標也不樂觀。
實測長文本理解錯誤率比GPT-4o高12%。多輪對話頻現「記憶斷裂」「上下文失聯」。
它在安全性和能力邊界之間,做了極度保守的權衡,換來的是泛用性模型的「及格表現」,卻錯失在單一場景內深扎能力的機會。
豆包已拿下50%的企業OA場景。阿里通義千問主攻醫療與客服問答。而DeepSeek仍在強調「通用AGI」,理想主義得像在搭建一個「人人可用」的科幻底座,卻始終落不到具體場景的「剛需點」上。
這不是模型能力的問題,而是路線選擇的問題。
在企業爭相搶奪政企、教育、金融、客服等「高頻剛需」領域時,DeepSeek還在用論文式訓練目標、OpenAI式開放語料庫、近乎宗教式的AGI設想與現實脫鉤。

它賭的是長期爆發,但現實是短期絞殺。
雲廠商拼SaaS交付效率、終端廠拼語音助手喚醒率、政府客戶要可控、安全、本地化部署,沒人再花時間「評測」你的哲學理想。
深度垂類落地這件事,已經在繞開它推進了。
開源成了一個好看的門面,企業客戶用你的模型調研開發,用完就上自家平台部署;開發者在社區做點實驗,一旦跑不動、精度差就換別家。
對DeepSeek來說,模型再強也只能是個「可替代工具」,不是「必選項」。
問題的核心不是沒技術,而是沒「被迫使用」的理由。
它像極了塞班時代的諾基亞,擁有強大內核,卻錯判了交互邏輯;也像特斯拉在FSD1.0時期,硬抗整個自動駕駛行業,只為搶先定義AGI語法。
但這次,它不再是唯一的特斯拉,也不是手機里的蘋果。
行業已經有太多可用方案,尤其是國產大模型生態,在2025年之後,已從「百模大戰」進入「場景圍獵」,從「能力卷」走向「鏈路搶」。
DeepSeek押注的,是2025年前能實現多模態重大突破。
它的終極願景,是像iPhone定義交互那樣,用AGI直接跳過所有垂直應用,以「萬金油」反包垂類冠軍。
問題是,現在這副牌,邏輯沒錯,但牌面不夠。
生態遲遲沒有閉環,場景落地跟不上節奏,調用量再多也是空耗算力、無法變現;而技術短板暴露的越明顯,被「邊緣化」的速度也會越快。
這不是「模型不夠強」,而是「模型沒人用」。
·End·
*以上內容系網友風平浪靜自行轉載自爆財局,該文僅代表原作者觀點和態度。本站系信息發布平台,僅提供信息存儲空間服務,不代表贊同其觀點和對其真實性負責。如果對文章或圖片/視頻版權有異議,請郵件至我們反饋,平台將會及時處理。